






 Zitieren
Zitieren

Ich habe die Dichtefunktionen der drei Sensoren für die erste Messung einmal aufgetragen, wobei das Integral der Kurven jeweils 1 ist. Das Integral der Wahrscheinlichkeitsdichte pro Intervall gibt an, wie hoch die Wahrscheinlichkeit ist, dass der Wert im entsprechenden Intervall liegt.
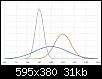
Zur Zusammenführung kann man grundsätzlich (!) für jedes Intervall berechnen, wie groß die Wahrscheinlichkeit ist, dass er es das richtige ist. Man erhält dadurch eine neue Dichtefunktion.
Bei nur einer Messung ist die Wahrscheinlichkeit für einen Wert höher als wenn noch eine Messung hinzukommt, die eine andere Aussage macht. Es kommt zu einer bedingten Wahrscheinlichkeit, für die die Werte miteinander multipliziert werden.
Das ist grundsätzlich interessant, für die aktuelle Aufgabe bin ich auch froh, dass es eine grundsätzliche Lösung in Wikipedia gibt.
(Das Beispiel deutet sicher auch auf eine systematische Abweichung hin, aber es dient ja hier wie beschrieben auch mehr zur Veranschaulichung.)


Lesezeichen